Hi
I have 5 node cluster where tservers are running and automatic tablet split are on and num shards per tserver is 1.
I have a partitioned table, master table tablet leaders split evenly, however 1 child table tablet leader did not split evenly at first.
After deleting the child table and recreating that child table again, tablet leaders split evenly.
I could not understand why uneven split happened at first. Please help me to understand.
What do you mean by “uneven”?
The dynamic tablet splitting mechanism should pick a midpoint based on the data, so if you have a lot of data on the lower end of the spectrum, the split point will be lower.
Is the table hash partitioned or range partitioned?
When recreating the table, did you CREATE TABLE AS or data load everything immediately compared to before?
The 5 servers IPs are xx.xx.xx.190,xx.xx.xx.191,xx.xx.xx.192,xx.xx.xx.193,xx.xx.xx.194
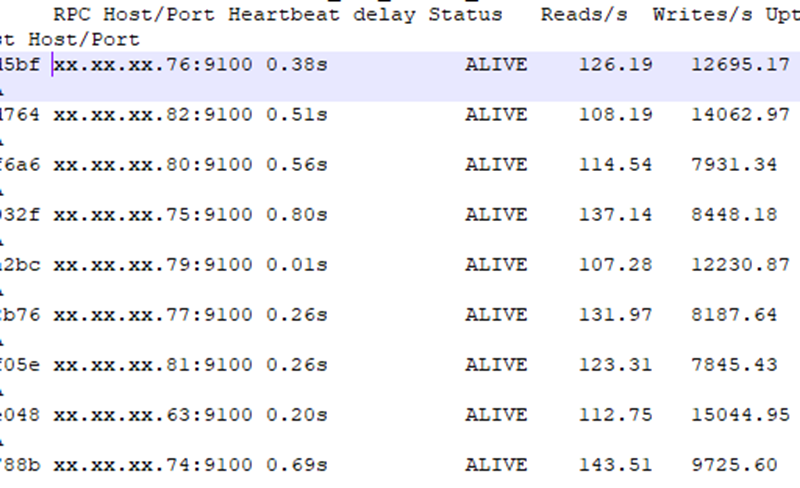
This can be seen that, among the 5 tserver nodes, 193 is totally absent in the list. most tablet concentration is in 190 node. But when we dropped the table and created once again, the distribution was fine after that. After loading data tablet split were fine and the distribution is also proper.
this table is a child table of range partitioned table. This is created with Create table <child_table_name> partition of <main_partitioned_table from (<dt_start>) to (<dt_end>);
Streaming data is being loaded in those tables through Kafka consumer.
Our question here is,
in what circumstances this may happen
if this type of skewed distribution resurfaces in future(production), then how to make sure that it gets rebalanced properly again.
If you use range partitioned tables, the default number of shards/tablets would be 1 (on the 2.20.1 builds that you are using). As data is loaded into the tablet, it can get split. Automatic tablet splitting works at a per tablet level, and it splits the tablet into 2 - the split point is currently derived from the data that is flushed to disk and if there is additional data that is already inserted to the table (but not yet flushed etc), that data might not influence the split point. The net result is that it can sometimes result in uneven splitting of data. We are looking at couple of cases of uneven splits, especially if the input data comes in an ascending or descending order. Chances of uneven splits would be low, if the input data is shuffled. Also, If you know the split points, then you can use them at the table creation time as mentioned in thee example in - Tablet splitting | YugabyteDB Docs.
Are you concerned about traffic not being spread across the nodes in the above case (when the split was uneven?).
Hi @Raghavendra_Thallam ,
The problems we faced is:
In one occasion one of the tservers didn’t have any leader.
In another occasion though other things are correct, one of the tservers doesn’t have any of the tablets including indexes (report is share in the above post).
Yes. traffic distribution also skewed. Due to this uneven split the throughput is going down drastically. Where we are getting ~8k steady inserts per second (even when 40+ crores of data is there in the table) after even distribution took place on truncating the tables, we were struggling to reach 2.2 K ingestion per second in uneven distribution.
What I do concern about is the a way to re-uniform it. In the long run it can happen that one tablet server is down for long and the skewedness crops up with newly created tables. Then what would be the remedy to make every thing in line again.
Do you have any logs from yb-master when 1 t-server did not have any leaders or tablets ? I’d be interested in seeing if the Load Balancer was trying to balance things out to ensure an even distribution of tablets.
Could you also share the output of http://:7000/tablet-servers and http://:7000/cluster-config
No. We have truncated the records and moved ahead. But we are facing skewed distribution issue. In different times have observed one tserver with no leader (the tablet distribution was ok here), among 5 tservers one is getting maximum leaders. We have added more nodes to force the rebalancing, but seems to have no use. The issue is the ingestion rate is dropping significantly.
Actually this will be a bigger installation of yugabyte replacing hive which should support more than 50k TPS.
Note that you’re describing 3 different issues here, and you need to provide details in all of them to see what’s going wrong.
This isn’t skewed distribution, something is wrong with the yb-tserver or cluster config.
Skewed distribution would be if some tablets are bigger than others. (we try to balance by number of leaders/peers per-node).
What we are doing wrong that tablet leaders did not distribute evenly between nodes in all zones.
Is there anything specific we can mention in tserver config to ensure evenly tablet Leader distribution between nodes in all zones? Like modify_placement_info?
If yes, is it possible to add that config in an already running cluster?
We see write speed is high in some nodes than others. What can we do to make it more even.
Do we need to follow anything specific while adding nodes to a cluster?
Thank you for your help in advance.
Can you explain what your requirements are in the deployment (multi-az/region, az-region failover, row-level geo-replication, etc)?
We should be able to fix an existing cluster, so yes.
After we get the screenshots, we’ll look at the schema/tables/indexes.
Example: maybe you have a global range index on a timestamp column so all new writes will also write to a single tablet (since new writes will have the latest timestamp).
Or maybe you shard by client_id a table, and 1 client is very heavy resulting in many writes to it’s tablet leader compared to other tablets.
Depends on the topology. If it’s just a single az, no.
We can also get on a call and look at the same things together. But we’ll still need the info requested above.
The following will really help us understand why you are experiencing an imbalance of leaders as well as tablet peers in the cluster:
Screenshot of http://master-ip:7000/tablet-servers : This will give us a few pieces of information - The Cloud/Region/Zone for each of your T-servers which is what the Load balancer uses to distribute tablet leaders and followers. This information typically comes from your t-server startup arguments. See example at YB-TServer manual start | YugabyteDB Docs.
Lastly, we wanted to check if the Load Balancer is trying to resolve the situation or not. While this will be evident from the master-logs, a quick view of the http://master-ip:/7000 page shows 2 pieces of information: “Load Balancer Enabled” and “Is Load Balanced?” which will be useful to understand the issue.
Hi Sandeep
PFB, screenshots related to point 1 and 3. And for point 2 we do not have any specific placement configuration in ybt and ybmaster conf. Please suggest if i am doing anything wrong.
There are 2 things that I see from the screenshots:
You see the ‘x’ mark for “Is Load Balanced ?” This is indicating that the Load balancer is still attempting to balance the load on the cluster. It would be a green tick mark if the cluster was fully balanced. You also see a message above the first screenshot saying “Cluster is not Balanced”
The first screenshot also seems to show that each zone almost has an equal number of tablets and leaders, so looks load is almost evenly distributed in the zone.
Hi Sandeep
Sorry for the late reply. PFB screenshots of tablet servers. Although load balancer is showing on, still cluster load is not balanced for long time.