1. Is there a way to bring back the node to normal? Also the load is not getting split after blacklisting.
And when I added a new Tserver its not receiving any load. Also newly added Tserver and few other Tservers does not have any system tablet leaders/peers.
Please suggest,
1. how to split load with newly added tserver.
2. Do we have to have System tablet Leader/peers in every Tserver? If yes, how to make sure System tablets gets splitted in all Tservers.
For many of your questions (like in this thread or previous threads), without knowing the http://master-ip:7000/cluster-config details, and COMPLETE output of http://master-ip:7000/tablet-servers it is not going to be obvious what the issue is. Based on earlier threads also it is most likely a case of misconfiguration. In future, can you always share those details for this flavor of question?
Regarding the node that you added to bring back to normal:
I am guessing you added the node to the blacklist using the ADD option of yb-admin utility’s change_blacklist command, correct?
To remove it from the blacklist and bring it back as a normal node, have you tried using the REMOVE option of the same command?
regarding blacklisted server, thanks for your suggestion removing the server then adding it worked.
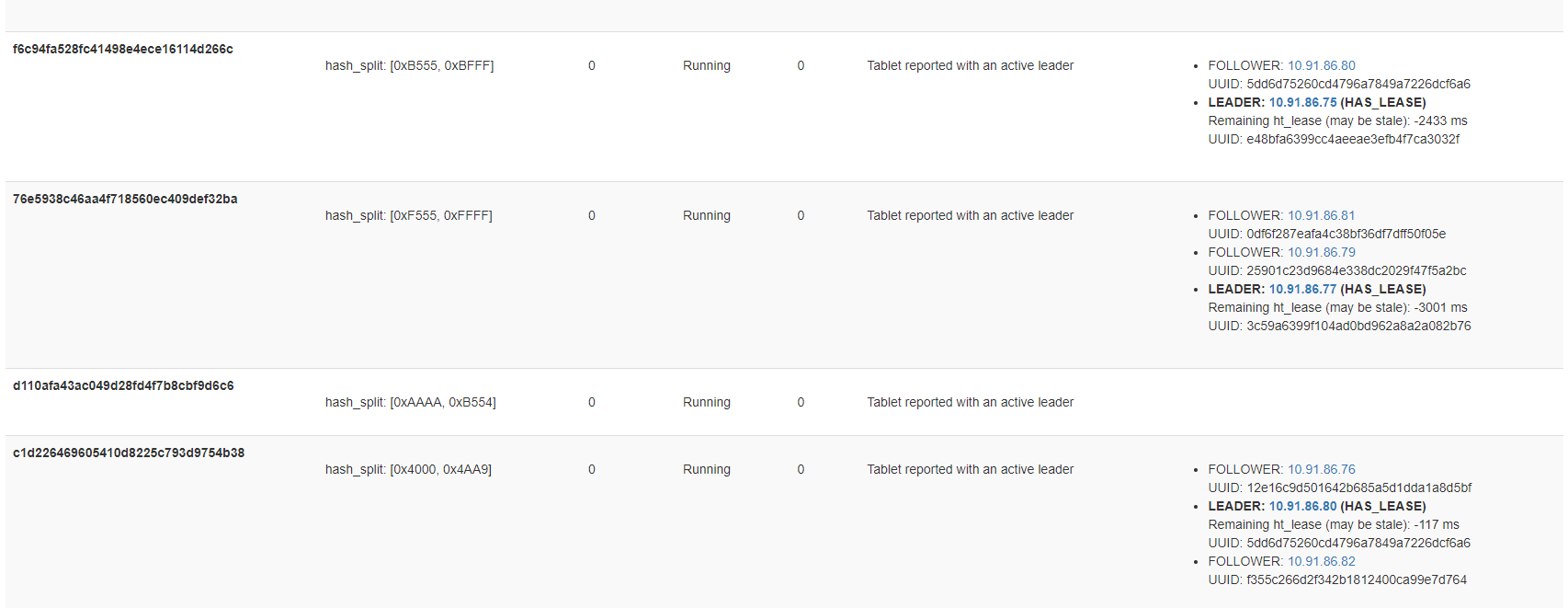
However, few nodes does not have any system tablet peers/leaders and also system transaction table is showing leader peer not found.
Inside that transaction table I see it says that tablet reported with an active leader, however no leader/follower details are there.
Also some of the transaction tablets only showing follower. I have attached screenshots of those.
a) Just an observation… from the /cluster-config, looks like, for this cluster you have not run the yb-admin modify_placement_info step to configure a zone aware data placement policy.
b) Separately, with respect to why you have leaderless tablets – it is possible (for example) that in a RF=3 configuration you had two concurrent node failures or some other issue that needs to be investigated. Note that an RF=3 configuration is designed to handle 1 concurrent failure. You’ll probably have to share the logs (yb-tserver & yb-master logs especially) for YB side folks to be able to help. Or, perhaps ping us on community slack channel, and some folks can help get on a call with your team to help investigate further.
Yes, I did not run modify_placement_info command separately this time. Actually it was working fine without specifically mentioning that command. I did execute this command to check if this makes cluster load balanced. It ended up being in read replica.
As you suggested, it did happen once that 2 master was down out of 3, also 3/4 Tservers were also down. I will share master log.
Is there a way I can make system tablets split between servers? like if I separately go for compact table system.transactions. Will it help solving Leaderless tablets, system.transactions? or is this even a right approach, manual compaction of system.transactions table?
Additionally, what I found that Insertion rate is decreasing gradually, and once I restart all Tservers, insertion rates increases and rate stays high for 2/3 hours, then it decreases again.
Please suggest.
But do you have any pending issues with the cluster still?
It’s not.
There is no information here. It should be very detailed, with exact numbers, how the inserts are spread over the servers, etc. It could be many things that go wrong (like compactions, or bad client code, or inserts going into 1 tablet, that after it gets split and the load is spread). Or maybe the load isn’t spread.
So would need a lot more details here.
I was thinking that if system tablets are not split evenly, it might affect cluster performance. So it is okay to have system tablets like this.
Inserts are spread over the servers more or less evenly, however insert rate drops suddenly and increases once all tservers are restarted. Could it be because of network issues?
It could be many things. You have to be really careful when benchmarking and see where the bottleneck is (network, disk io, CPU usage, bad client code, not enough parallelism, too much concurrency on single rows/tablets/server/load-balancer, bad configuration somewhere in the stack, etc etc).